 さて、今回は受け取ったデータを切り分けて使えるようにします。
ただし、まだ入力される文字は半角英数字のみで、へんてこな記号にも対応していません。
さて、今回は受け取ったデータを切り分けて使えるようにします。
ただし、まだ入力される文字は半角英数字のみで、へんてこな記号にも対応していません。
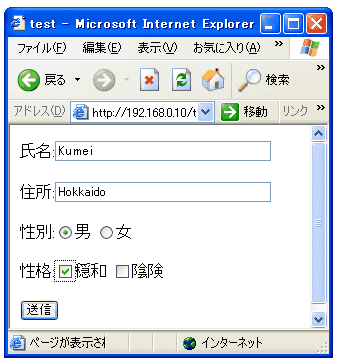
まずは、入力のためのページを作りますが、これは前章とほとんど同じです。
<HTML> <HEAD> <meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS"> <TITLE>test</TITLE> </HEAD> <BODY> <FORM METHOD="POST" ACTION="cgi03.cgi"> 氏名:<INPUT TYPE="TEXT" SIZE="40" NAME="namae"><P> 住所:<INPUT TYPE="TEXT" SIZE="40" NAME="jusho"><P> 性別:<INPUT TYPE="radio" NAME="SEX" VALUE="MALE">男 <INPUT TYPE="radio" NAME="SEX" VALUE="FEMALE">女<P> 性格:<INPUT TYPE="checkbox" NAME="ONWA">穏和 <INPUT TYPE="checkbox" NAME="INKEN">陰険<P> <INPUT TYPE="SUBMIT" VALUE="送信"> </FORM> </BODY> </HTML>
タグの間違いがあれば、各自修正しておいてください。
さて、上図のように入力したあと「送信」ボタンを押すと次のような表示になります。
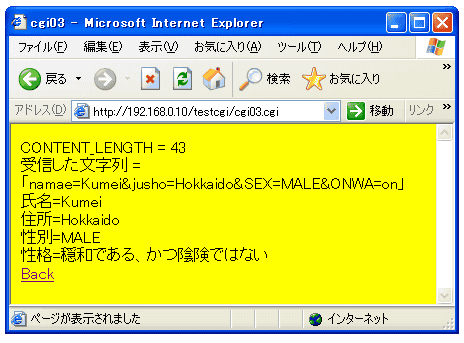 単なる文字列の切り分けですが、これが結構つまらないバグが生じたりして
手間取ることがあります。特に受信した文字列の最後に余計な文字(改行文字など)が含まれていたりするのをそのまま処理すると思わぬエラーが生じたりします。
単なる文字列の切り分けですが、これが結構つまらないバグが生じたりして
手間取ることがあります。特に受信した文字列の最後に余計な文字(改行文字など)が含まれていたりするのをそのまま処理すると思わぬエラーが生じたりします。
PerlでChompとかいうのが存在する意味がよくわかります。
また、全部空欄にして「送信」ボタンを押すと次のような表示になります。
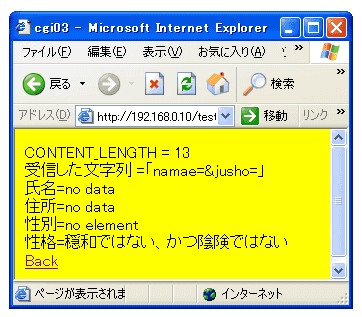 空欄であったところには「no data」と表示します。また、探しているフォームの要素名
そのものが見つからなかったときは「no element」と表示します。
空欄であったところには「no data」と表示します。また、探しているフォームの要素名
そのものが見つからなかったときは「no element」と表示します。
さて、受信した文字列の最後に変な文字が付いているときは、この空欄で問題を 起こします。暇があったら実験してみてください。
では、プログラムのソースを見てみましょう。
// cgi03.c
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
#include <string.h>
int getstring(char *, char *, char *);
int er();
int main()
{
int i, len;
char c;
char *pBuf;
char name[64], address[256], sex[16], onwa[16], inken[16], seikaku[128];
len = atoi(getenv("CONTENT_LENGTH"));
//あまりにも多いデータが送られてきたときはエラーとする
if (len == 0 || len >= 1024) {
er();
return 0;
}
//データを格納するバッファを動的に確保
pBuf = (char *)malloc(len + 1);
if (pBuf == NULL) {
er();
return 0;
}
//データを受け取る。
//このとき改行文字等は除外しないと後で思わぬエラーが生じる
for (i = 0; (c = getchar()) != EOF; i++) {
if (c != '\r' && c != '\n')
pBuf[i] = c;
else
i--;
}
//送られてきたデータの最後にはヌル文字がないので自分で付ける
pBuf[i] = '\0';
//生データから欲しいデータの文字列を切り分ける
getstring(pBuf, "namae", name);
getstring(pBuf, "jusho", address);
getstring(pBuf, "SEX", sex);
getstring(pBuf, "ONWA", onwa);
getstring(pBuf, "INKEN", inken);
if (strcmp(onwa, "on") == 0)
strcpy(seikaku, "穏和である");
else
strcpy(seikaku, "穏和ではない");
if (strcmp(inken, "on") == 0)
strcat(seikaku, "、かつ陰険である");
else
strcat(seikaku, "、かつ陰険ではない");
//HTML表示用
printf("Content-type:text/html\n\n");
printf("<HTML>\n");
printf("<HEAD>\n");
printf("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=Shift_JIS\">\n");
printf("<TITLE>cgi03</TITLE>\n");
printf("</HEAD>\n");
printf("<BODY BGCOLOR=\"#FFFF00\">\n");
printf("CONTENT_LENGTH = %d<BR>\n", len);
printf("受信した文字列 =「%s」<BR>\n", pBuf);
printf("氏名=%s<BR>\n", name);
printf("住所=%s<BR>\n", address);
printf("性別=%s<BR>\n", sex);
printf("性格=%s<BR>\n", seikaku);
printf("<A HREF=\"javascript:history.go(-1)\">Back</A>\n");
printf("</BODY>\n");
printf("</HTML>\n");
//確保したメモリの解放
free(pBuf);
return 0;
}
getstringというのは次に出てくる自作関数です。
これに、元データ、欲しい要素、受け取るバッファを指定します。関数側では受け取りバッファのサイズの確認をしていないので十分大きな バッファを渡すようにしてください。
getenv関数は次のようになっています。
char *getenv(const char *varname);varnameに、環境変数名を指定します。 POST形式のフォームから入力されたデータのバイト数はCONTENT_LENGTHで求めることかができます。この関数の戻り値のデータ型を見てもわかりますが、文字列として 返されるので、これをatoi関数で数値に変換する必要があります。atoi関数に 付いては第34章に少しだけ出ています。
次に送信されたバイト数が必要以上に大きい場合は、サーバーの付加も考えて 受け付けないようにします。ここでは、er関数を呼んでmain関数を抜けています。
次に元データを受け取るバッファを用意します。あらかじめ配列で用意しておいても よいのですが、ここでは動的にメモリを確保することにします。
malloc関数については第33章を参照してください。 これも、メモリの確保に失敗したらer関数を呼んで処理を中止します。
さて、標準入力からgetchar関数で用意したバッファに読み込みますが、 改行文字等は読み飛ばすことにします。
生データがバッファに用意されたらこれを必要に応じて切り分ければよいことになります。ここでは、getstring関数を作ってみました。
欲しいデータが用意されたらあとは、HTML表示用の出力をすればよいことになります。 最後にmallocで確保したメモリの解放を忘れないようにします。
int getstring(char *src, char *element, char *dest)
{
int len;
char *data, *amp;
char *temp;
len = (int)strlen(src) + 1;
temp = (char *)malloc(len);
len = (int)strlen(src);
if (len >= 1024) {
er();
free(temp);
return -1;
}
strcpy(temp, src);
data = strstr(temp, element);
if(data == NULL) {
strcpy(dest, "no element");
free(temp);
return -2;
}
len = (int)strlen(element) + 1;
amp = strstr(data, "&");
if (amp == NULL) {
strcpy(dest, data + len);
if (dest[0] == '\0') {
strcpy(dest, "no data");
free(temp);
return 0;
}
free(temp);
return 1;
}
data[(int)(amp-data)] = '\0';
strcpy(dest, data + len);
if (dest[0] == '\0') {
strcpy(dest, "no data");
free(temp);
return 0;
}
free(temp);
return 0;
}
生データを切り分ける関数です。
srcは生のデータ、elementは欲しいデータの要素名、その結果を格納するのがdestです。生データを処理すると元のデータも壊れてしまうので、生データのコピーを 取ることにします。生データの大きさを調べてコピー用のバッファを用意します。
そして、このバッファに生データをコピーして、いろいろな処理はこのコピーを 使うことにします。
まず、コピーされたデータ中に希望する要素名が含まれているかどうか 調べます。これにはstrstr関数が便利です。
char *strstr( const char *string, const char *strCharSet );stringには、検索対象文字列を指定します。strCharSetには、検索する文字列を指定します。
戻り値は検索文字列が最初に出現するポインタです。
文字列が見つからなかったときはNULLが返されます。また、strCharSetが長さ0の文字列であった場合はstringが返されます。
ここでは、要素名が見つからないときはdestに「no element」と書き込むようにしました。
さて、要素名が見つかったら要素名の長さを調べます。データは「要素名=data&要素名=data&...」という形なので、欲しい文字列は要素名のポインタから「要素名の長さ+1」バイトだけ進んだところから始まります。また、次の要素名との境目には「&」があるので この位置も調べる必要があります。
欲しいデータの要素名のボタン他をp1、次の&のポインタをp2とすると p1[(int)(p2-p1)]の文字を「\0」に置き換えてやると、p1が目的の文字列です。
さて、欲しい要素名が最後にあると次の「&」は存在しません。 この場合欲しい文字列は「p1+要素名の長さ」ということになります。この時 元データの最後に改行文字等が付いていると変なバグが生じます。
さて、これで文字の切り分けは終わりです。もっと効率のよい方法があると思いますのでいろいろ工夫してみてください。
int er()
{
printf("Content-type:text/html\n\n");
printf("<HTML>\n");
printf("<HEAD>\n");
printf("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=Shift_JIS\">\n");
printf("<TITLE>Error</TITLE>\n");
printf("</HEAD>\n");
printf("<BODY BGCOLOR=\"#FF0000\">\n");
printf("error!");
printf("</BODY>\n");
printf("</HTML>\n");
return 0;
}
エラー発生時のHTML出力用関数です。これでは、エラーが発生したのはわかっても、どのようなエラーなのか わかりません。er(char *)のように引数を取って、エラーの種類がわかるように 工夫してみてください。
さて、今回のCGIは漢字には対応していません。フォームに漢字を入力した 場合どのようになるか観察してみてください。
Update Aug/05/2002 By Y.Kumei